简介
在了解Java的集合框架(JCF, Java Collections Framework)之前,我们先了解一下什么是集合。集合是一组可变数量的数据项(也可能是0个)的组合, 这些数据项可能共享某些特征,需要以某种操作方式一起进行操作。集合与数组同样都能够用来存储、检索和操作数据,但与数组不同的是,集合的数量是可变的。
那么什么是集合框架呢,集合框架是一个统一的体系结构,用来表示和操作集合。集合框架一般会包含
- 接口:用来表示集合的抽象数据类型。
- 实现:接口的具体实现,本质上是一些可重用的数据结构。
- 算法:执行计算的方法,比如说检索和排序,本质上是可重用的功能。
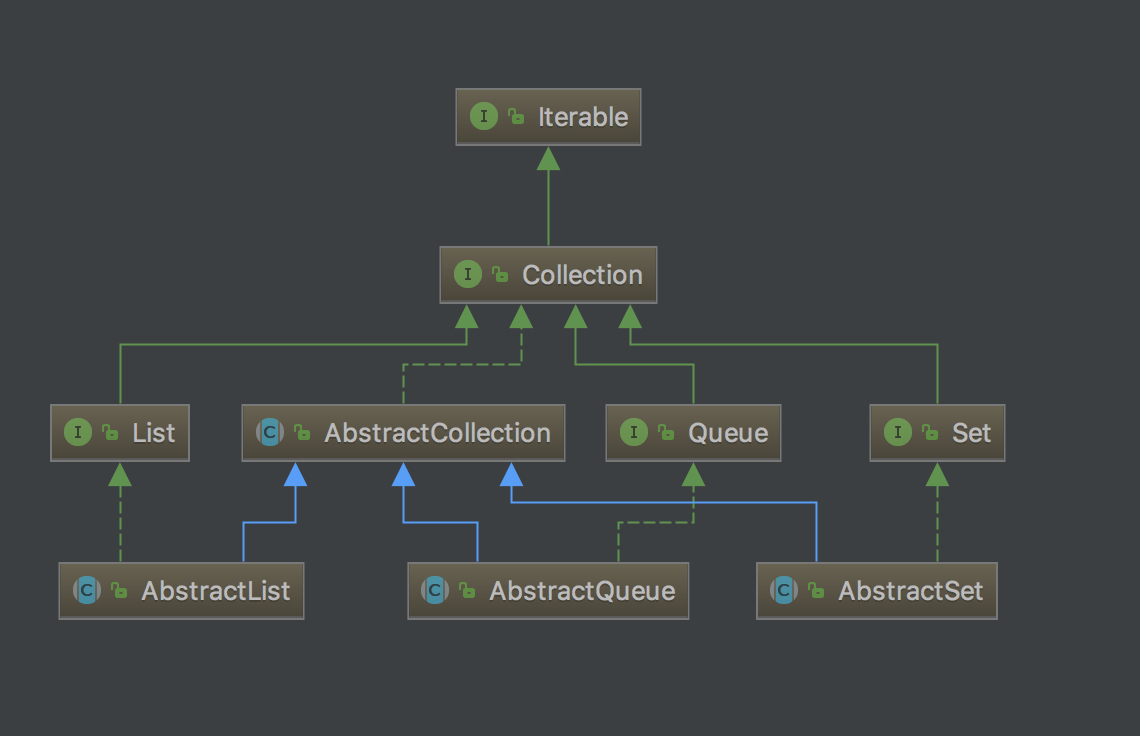
在Java集合框架中,最核心的接口有两个:Collection和Map,按照元素是否有序,Collection又派生出有序的List、Queue,以及无序的Set三个核心接口。
需要注意的是,Map并不属于Collection这个体系中,它与Collection是相互独立的两个接口,不像List等接口继承自Collection。
Collection接口中定义了以下方法:
- 基本操作
- int size()
- boolean isEmpty()
- boolean contains(Object element)
- boolean add(E element)
- 返回true:如果添加成功并且集合发生了改变,
- 返回false:集合不允许重复元素 && 集合中已包含要添加的元素。
- boolean remove(Object element)
- 返回true:从集合中成功移除元素,集合发生了改变。
- boolean equals(Object o)
- int hashCode()
- 遍历
-
聚合:JDK8及以后可以使用集合获取一个Stream,在Stream上使用聚合操作进行遍历,通过集合的 Stream
stream()、Stream parallelStream() 方法获取Stream。 myShapesCollection.stream() .filter(e -> e.getColor() == Color.RED) .forEach(e -> System.out.println(e.getName())); -
for-each:
for (Object o : collection) System.out.println(o); -
迭代器:迭代器支持在遍历集合的同时从集合中删除元素。迭代器通过集合的 Iterator
iterator() 方法获取。 for (Iterator<?> it = c.iterator(); it.hasNext(); ) if (!cond(it.next())) it.remove();
-
- 批量操作
- boolean containsAll(Collection<?> c)
- boolean addAll(Collection<? extends E> c)
- boolean removeAll(Collection<?> c)
- boolean retainAll(Collection<?> c)
- 保留目标集合中与入参集合c的交集元素,删除目标集合里不包含在入参集合c中的元素。
- void clear()
- 数组操作
- Object[] toArray()
-
T[] toArray(T[] a)
在了解集合Collection中定义的方法后,我们来深入由Collection派生出的其他三个接口特性及其主要实现。
Set
Set接口继承自Collection,且仅包含Collection中定义的方法,但是限制了不能有重复元素,即Set是不包含重复元素的集合。
同时,Set也为equals和hashCode两个方法增加了更强的契约,约定包含相同元素的两个Set即相等。
Set接口有三个通用实现,分别是HashSet、TreeSet和LinkedHashSet,以及两个特殊用途的Set实现,EnumSet和CopyOnWriteArraySet。
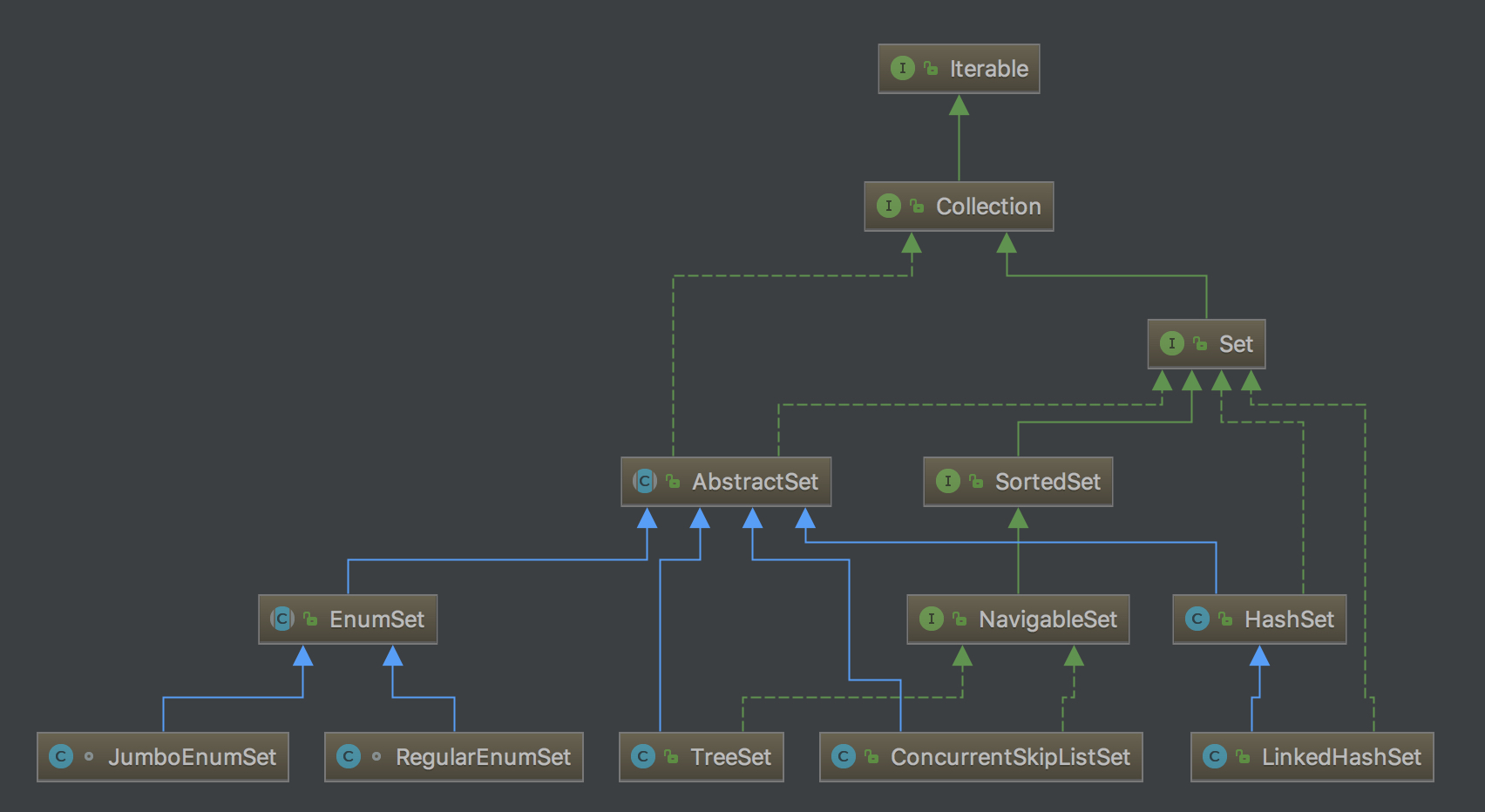
HashSet
HashSet是最通用的Set实现,将数据存储在哈希表中,是性能最好的实现,但是不保证元素的顺序。
TreeSet
TreeSet是SortedSet的一个实现,顾名思义,它使用红黑树来存储元素,所以能够基于元素的value进行排序(value-ordered),因而 TreeSet要比HashSet慢。
LinkedHashSet
LinkedHashSet是HashSet的一个子类,在HashSet的基础上增加了一个链表,配合哈希表一起实现Set集合中元素按照插入顺序排序(insertion-order), 排序方式不同于TreeSet,cost也远比TreeSet小,但比HashSet略大。
EnumSet
EnumSet是Set的一个高性能实现,批量操作也可以在常量时间内完成,其内部表示为位向量。但是EnumSet的元素只能为同一个枚举类型。 由EnumSet衍生出两个私有实现,JumboEnumSet和RegularEnumSet。当所传入的枚举类的枚举常量个数小于等于64时,内部使用RegularEnumSet ,否则使用JumboEnumSet(RegularEnumSet内部使用long类型来作为位向量,因而是64位)。
CopyOnWriteArraySet
CopyOnWriteArraySet是Java concurrent包下对Set的一个线程安全的实现,每个会更改Set的操作,比如add、remove、set等操作都会复制出一个新的数组副本, 因而可以安全的插入和删除元素。然而通过Iterators遍历时,不允许插入或删除数据且不能避免来自别的线程的干扰。 当CopyOnWriteArraySet的size越大时,add、remove、contains等操作所消耗的时间也越久,所以只适合数据量小且很少修改的场景。 其中contains操作消耗时间是因为其内部是一个CopyOnWriteArrayList,不同于HashSet的HashMap,contains 操作需要遍历其内部List因而消耗时间,也因为内部是CopyOnWriteArrayLis所以CopyOnWriteArraySet是按插入顺序有序的(insertion-order)。
List
List接口也继承自Collection,但与Set不同的是,List是有序且允许包含重复元素的。除了Collection接口中定义的方法,List还支持以下操作:
- Positional access:List可以基于元素在list中的位置来操纵元素,比如get、set、add等方法。
- Search:可以在List中搜索一个特定元素,返回其位置,比如indexOf和lastIndexOf方法。
- Iteration:ListIterator继承了Collection中定义的迭代器Iterator,并利用了List的顺序特性,提供一些特有的操作,比如向前遍历。
- Range-view:sublist返回List上的一个任意区间,sublist(int fromIndex, int toIndex),两个参数表示一个半闭半开区间。
List有两个通用实现,ArrayList和LinkedList,以及CopyOnWriteArrayList、Vector、Arrays内部实现的ArrayList(Arrays.asList)
三种特殊实现。
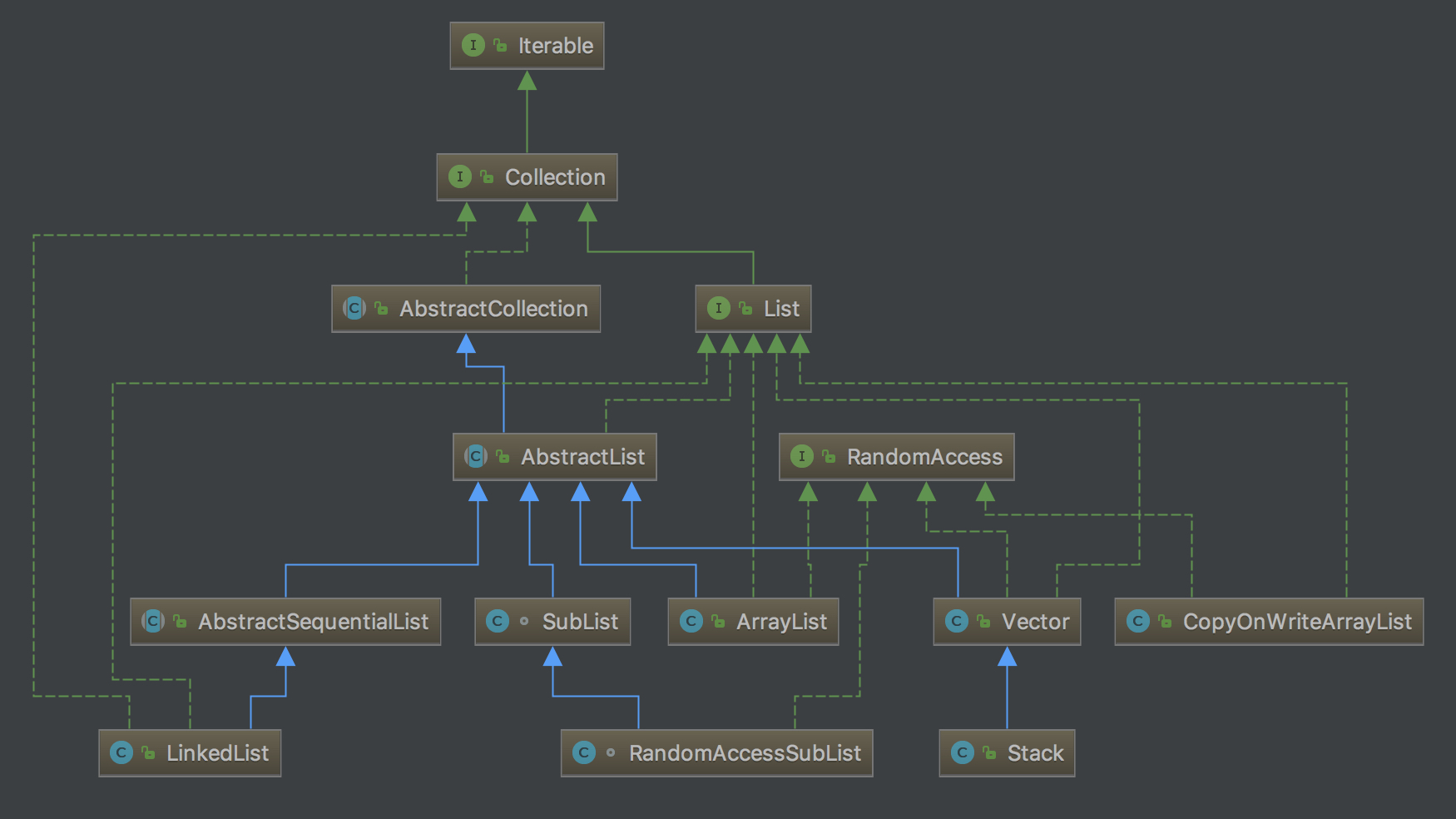
ArrayList
ArrayList是List的一个通用实现,大多数情形下我们都可以使用它,它提供了常数时间内的位置访问,当需要同时移动多个元素时(比如内部空间不足需要重新分配一块较大内存, 将元素全部复制到新内存块里时),会使用native方法System.arraycopy,因而ArrayList有一个调优参数:init capacity。
LinkedList
LinkedList是List的另一个通用实现,比较适合需要经常从List头部插入元素或从List中间删除元素的场景,这些操作ArrayList需要线性时间而LinkedList只需要常量时间。 然而LinkedList的位置访问需要线性时间,比较耗性能,所以使用时需要权衡利弊在LinkedList和ArrayList合理选择。LinkedList同时也实现了Queue接口。
CopyOnWriteArrayList
CopyOnWriteArrayList与CopyOnWriteArraySet类似,都是Java concurrent包下提供的线程安全的实现。在写操作到来时CopyOnWriteArrayList获取内部的ReentrantLock,以此避免多个写操作直接的并发问题。这种实现比较 适合于变更不频繁的场景。
Vector
Vector可以看做是ArrayList的线程同步版本,它的读写操作都使用synchronized原语修饰,因而保障了线程安全,但也因此造成了性能损耗,所以Vector要比ArrayList 慢很多。与CopyOnWriteArrayList不同的是,Vector读写操作都会加锁,这意味着当写操作获取锁后,一直到写操作完成否则读操作会被阻塞,而CopyOnWriteArrayList 中读操作则不会被阻塞。
Arrays.asList
Arrays.asList将会返回一个Arrays类内部实现的ArrayList,此ArrayList的size固定,也就是意味着不可以进行add、remove等操作。
Queue
Queue接口也继承自Collection接口,它定义了队列的数据结构,会按照元素插入的顺讯存储数据,是一个FIFO(first-in first-out)系统, 即插入元素会追加至队列尾部,删除元素会从队列头部开始。Queue有两个个重要的子接口Deque和BlockingQueue。Deque是一个双端队列,也就是插入和删除可以发生在队列头部或尾部。 BlockingQueue是Java concurrent下提供的一个阻塞队列,可以支持插入和删除操作的阻塞。
队列有三类基本方法:插入、删除、检查(检查类似删除操作,返回队列头的第一个元素,但不进行删除)
| 操作 | 失败时抛异常 | 失败时返回null或false |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 删除 | remove() | poll() |
| 检查 | element() | peek() |
可以看到,null是一个特殊返回值,所以队列中不允许插入null元素(除了LinkedList)。
队列的实现分为通用实现和并发实现,通用实现比如LinkedList和PriorityQueue,并发实现如LinkedBlockingQueue、ArrayBlockingQueue 等。
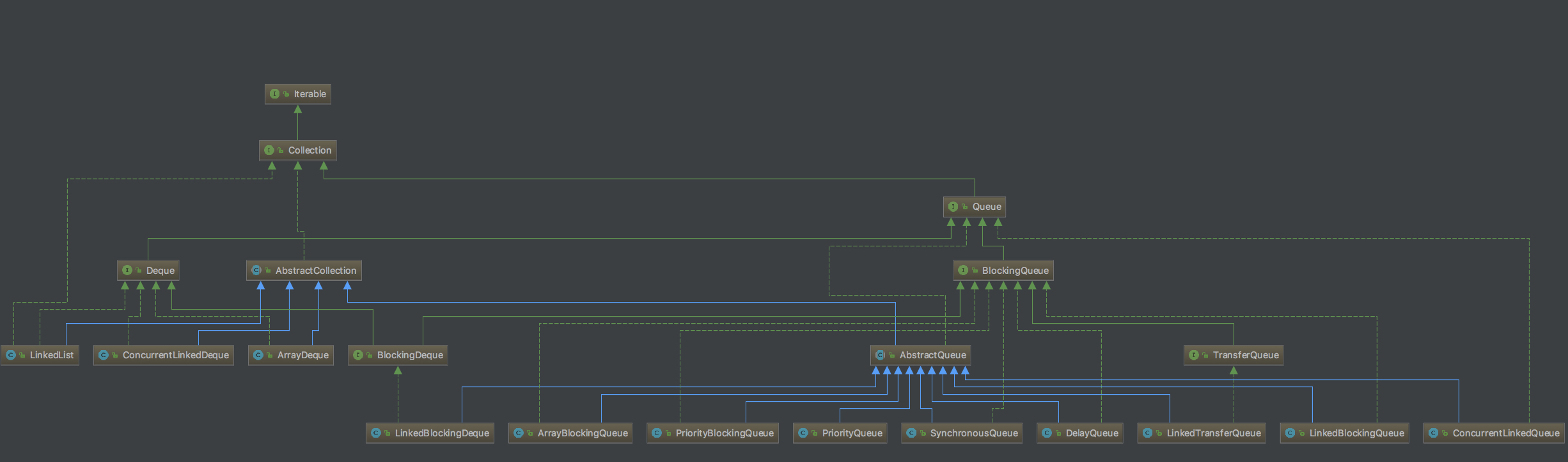
PriorityQueue
PriorityQueue是基于堆结构的优先队列,它可以按照构建时传入的比较器(Comparator)进行排序,当不指定比较器时,按照自然序排。
值得注意的是,PriorityQueue使用迭代器进行遍历时,遍历的元素顺序是无法得到保障的,
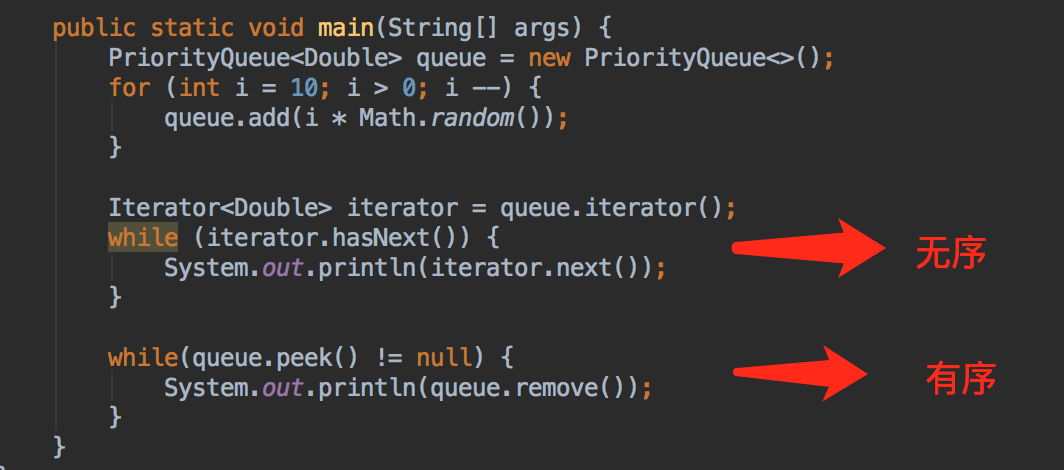
Map
Map将key映射为value,不允许包含重复key,因为一个key最多只能映射为一个value。Map不继承Collection接口,是Java Collections Framework里的另一个独立的体系结构。但与Collection类似,Map接口也定义了一些基本方法和批量方法。 Map中定义的方法:
- 基本操作:
- put
- get
- containsKey
- containsValue
- size
- isEmpty
- equals:两个Map代表了相同的key-value映射则认为相同,无论两个Map是否是相同类型的实现。
- hashcode
- 批量接口:
- clear
- putAll
- replaceAll
- 集合视图
- keySet
- values
- entrySet
Map有三个通用实现,HashMap、LinkedHashMap、TreeMap,除此之外还有一些特殊用途的实现,比如EnumMap、WeakHashMap、IdentifyHashMap ,还有一大类是java.util.concurrent包内ConcurrentMap接口的实现,在并发场景下使用,如ConcurrentHashMap。
HashMap
HashMap是Map接口最常用的一个实现,它不保障map中的元素顺序,且不保障线程安全。HashMap内部是一个Entry数组,每个Entry持有 一个key、一个value、一个next指向下一个Entry以及一个hash值。hash值是调用内部的hash方法计算得到的,具体实现是将key的hashCode 与其高16位进行异或, 得到一个int值。
LinkedHashMap
LinkedHashMap与HashMap类似,不过LinkedHashMap可以支持按输入顺序或按访问顺序进行遍历。
TreeMap
TreeMap是一个有序Map,它支持按map中的key的顺序进行遍历,内部使用了红黑树来保障顺序。
EnumMap
EnumMap是一类特殊的map,其key只能是枚举类型,内部使用一个数组,性能非常好。
ConcurrentHashMap
ConcurrentHashMap是Java并发包里一个线程安全版实现,性能比HashTable高,都是基于synchronized去加的锁。
QA
-
为什么CopyOnWriteArrayList写时复制就能实现线程安全?
在写操作到来时,CopyOnWriteArrayList获取内部的ReentrantLock,以此避免多个写操作直接的并发问题。 获取锁后再内部创建出一个副本将已有的元素复制进去,然后更改内部数组的引用地址指向新建出的副本,此后更改对读操作可见, 也就是在获取锁到写操作完成这段时间内,读操作都会读取到未更改的数据。 -
LinkedHashMap是怎么实现按输入顺序或访问顺序进行遍历的?
LinkedHashMap内部使用了一个双向链表来记录顺序,持有head和tail分别指向头Entry节点及尾部Entry节点,每个Entry内部也会有一个before和after分别指向 前一个Entry及后一个Entry。遍历时从head指向的Entry开始依次向后查询就可以了。 实现按输入顺序有序时,如果向map中put一个新节点时,会首先创建一个新的节点,创建之后将该节点链到tail之后,使新节点变为新的tail。LinkedHashMap没有 重新实现put方法,但是重写了get、newNode、afterNodeInsertion、afterNodeRemoval、afterNodeAccess等方法,以维护内部的这个双向链表。 -
为什么说ConcurrentHashMap性能比HashTable好?
HashTable中的get和put方法都是被synchronized修饰的,也就是每次get、put操作都会加锁,而ConcurrentHashMap只有put 操作加锁,且synchronized是加在bucket中第一个Node上的。也就是说,ConcurrentHashMap读操作是不会被锁的,以及同时put两个元素时,如果这两个元素key值hash 后落在两个不同的bucket中,它们彼此不会争用同一把锁, put操作可以同时进行。而HashTable中get和put操作都有可能被阻塞。
参考资料: