前段时间负责了一个项目,预测QPS会比较高,上线之前也进行了压测,QPS压到22w系统还很稳定,并且仍有一些余力,已经满足业务需求。
信心满满,本以为不会出任何问题,结果上线活动一开始,系统就直接崩了,记录一下本次故障的现象和原因。
故障现象
用户侧
- 页面无法进入,大量接口报超时。
基础云服务(阿里云)
- SLB,故障期间流量断层下跌

- MySQL和Redis故障期间运行平稳,流量略有下降。
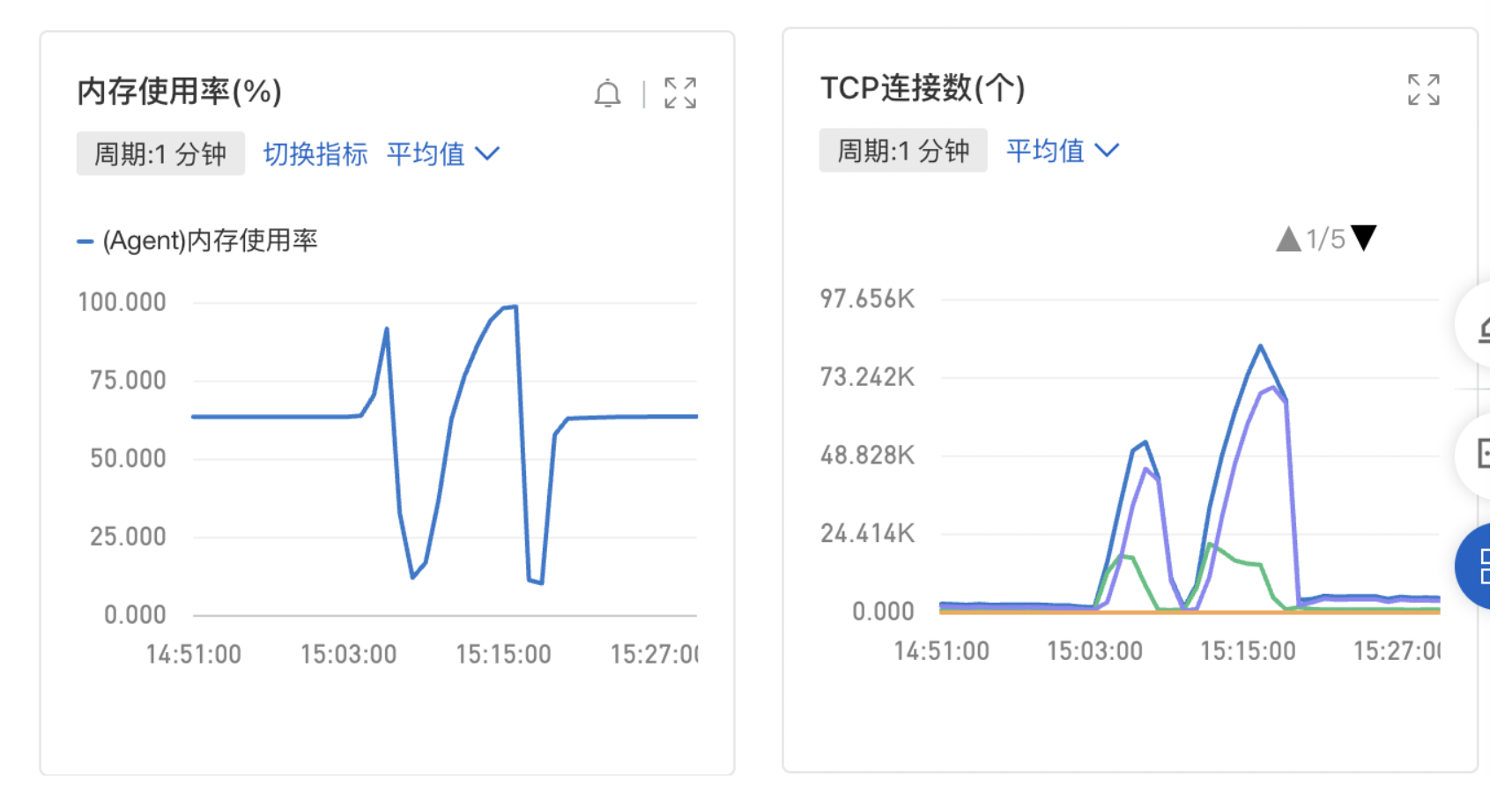
- ECS内存使用飙到100%,TCP连接数也暴涨。(图里的下降是因为重启过服务)
业务服务(Java服务)
- 流量与SLB基本一直,故障期间也有断层下跌。
- 从日志里看到,大量接口RT异常,好几十秒。
- 接口也有报错,大部分是Jedis报”Could not get a resource from the pool”。
故障原因
进过各种排查和压测复现,最终定位到直接原因是接入的阿里云验证码服务并发数不够,拖慢 & 拖垮了整个Java服务。
阿里云sdk的重要参数,com.aliyuncs.http.HttpClientConfig中
public static final long DEFAULT_CONNECTION_TIMEOUT = 5000;
public static final long DEFAULT_READ_TIMEOUT = 10000;
private int maxIdleConnections = 5;
private long maxIdleTimeMillis = 60 * 1000L;
private long keepAliveDurationMillis = 5000L;
/**
* timeout
**/
private long connectionTimeoutMillis = DEFAULT_CONNECTION_TIMEOUT;
private long readTimeoutMillis = DEFAULT_READ_TIMEOUT;
private long writeTimeoutMillis = 15000L;
/**
* dispatcher
**/
private int maxRequests = 64;
private int maxRequestsPerHost = 5;
对应到com.aliyuncs.http.clients.ApacheHttpClient,则是
RequestConfig requestConfig = RequestConfig.custom().setProxy(proxy).setConnectTimeout(connectTimeout).setSocketTimeout(
readTimeout).setConnectionRequestTimeout((int) clientConfig.getWriteTimeoutMillis()).build();
//...省略了其他代码...
connectionManager = new PoolingHttpClientConnectionManager(socketFactoryRegistryBuilder.build());
connectionManager.setMaxTotal(clientConfig.getMaxRequests());
connectionManager.setDefaultMaxPerRoute(clientConfig.getMaxRequestsPerHost());
对着这个文档接入时,并没有注意这些参数。
文档里提及”您可以调用带有connectTimeout和readTimeout的构造方法来自定义设置SDK调用接口的连接超时时间和读取超时时间”,没找到对应的构造方法,也就忽略了,然后使用了默认值 。
在这里阿里云提供了如何配置HttpClientConfig的demo,跟上面的接入文档不在同一处,太坑了。
真是惨痛的教训。
问题追问
Q1:为什么压测没测出问题?
因为阿里云的验证码服务是按调用次数收费的,压测的时候为了省钱,就跳过了没调用。
Q2:为什么接口的RT暴涨了?
活动开始时,会对每个用户进行一次验证,调用阿里云的验证码服务。
从上面的参数可以看到,验证码服务的并发数是5(maxRequestsPerHost),单次调用的平均耗时大约100ms,也就是单机QPS为5 * (1000 / 100) = 50。 这显然是不够用的,大量请求都在等待,最多会等待15s(ConnectionRequestTimeout)。
Q3:为什么其他接口的RT也暴涨了?
这个问题的原因比较复杂,推测跟Java21的虚拟线程及其调度有关,之后会再详细写一下。
Q4:为什么流量会断层下跌?
无论是SLB还是业务日志,都是请求处理完成、返回响应时记录的。故障期间,接口的RT暴涨,所以QPS就断层下跌了。
这也是ECS的TCP连接数会暴涨的原因。活动开始时大量用户涌入,而此时业务接口RT暴涨,TCP连接一直被占用着,无法被复用/释放,SLB就会与业务服务器建立新的TCP连接来处理新的请求。
Q5:为什么ECS的内存会飙升到100%?
从jmap dump的文件中来看,byte[]和char[]占了将近百分之77%的jvm内存。
有个猜想待验证:业务系统会打日志记录接口请求/响应数据,大量请求堆积时,持有很多字符串未释放,所以就内存飙升了。