前几天突然收到了线上接口错误报警,错误量不多,但一直在持续,点开日志一看,发现是SQL执行超时
org.springframework.dao.RecoverableDataAccessException:
### Error updating database. Cause: com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure
The last packet successfully received from the server was 2,002 milliseconds ago. The last packet sent successfully to the server was 2,002 milliseconds ago.
### The error may involve xxx -Inline
### The error occurred while setting parameters
### SQL: update tableXXX set xxx where user_id = ? and book_id = ? and topic_id = ?
### Cause: com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure
The last packet successfully received from the server was 2,002 milliseconds ago. The last packet sent successfully to the server was 2,002 milliseconds ago.
; Communications link failure
The last packet successfully received from the server was 2,002 milliseconds ago. The last packet sent successfully to the server was 2,002 milliseconds ago.; nested exception is com.mysql.cj.jdbc.exceptions.CommunicationsException: Communications link failure
The last packet successfully received from the server was 2,002 milliseconds ago. The last packet sent successfully to the server was 2,002 milliseconds ago.
at org.springframework.jdbc.support.SQLExceptionSubclassTranslator.doTranslate(SQLExceptionSubclassTranslator.java:100)
......
日志显示超时的SQL是:
update tableXXX set xxx where user_id = ? and book_id = ? and topic_id = ?
为什么update会超时
这简直太神奇了,这个表(user_id, book_id, topic_id)是加了唯一索引的,根据唯一索引update一行数据,竟然还能超时?
打开阿里云的数据库监控,发现了可疑的锁等待
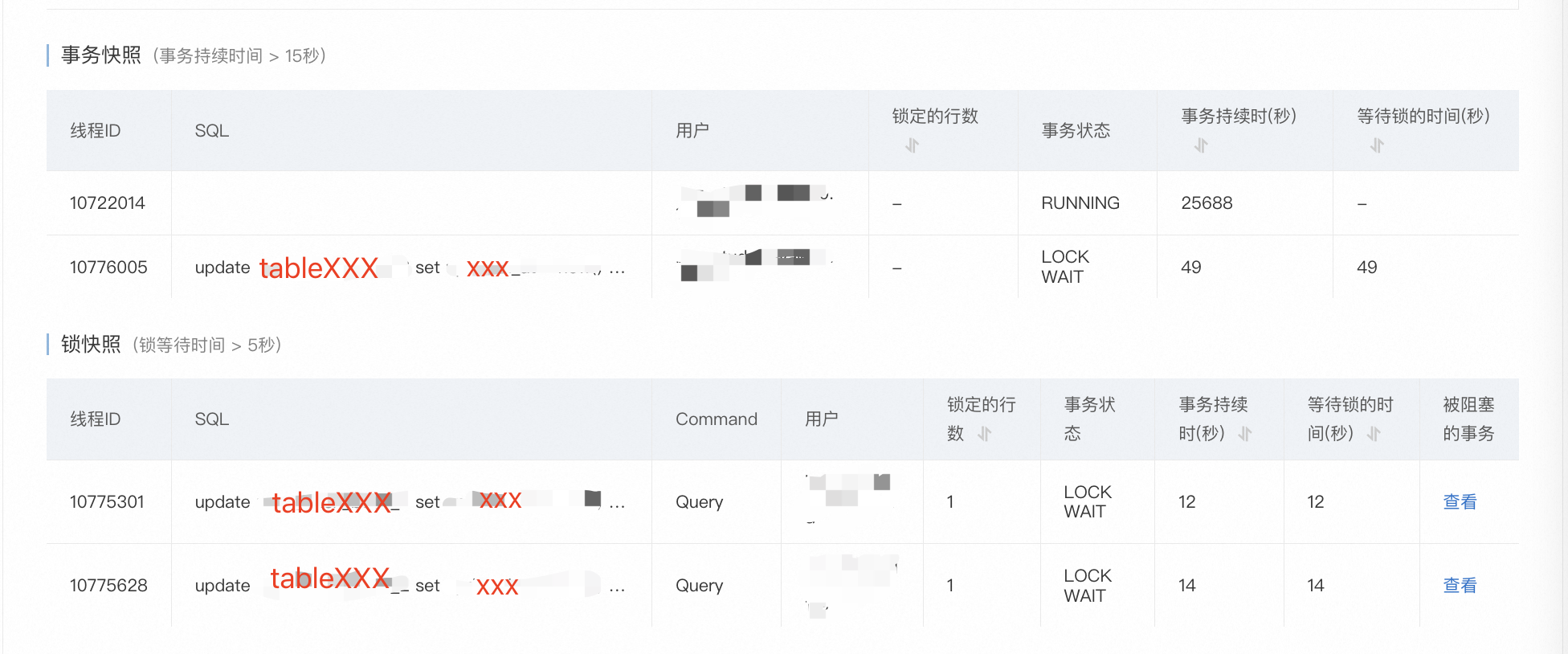
3个事务都在执行我这个update,最长的事务已经等了49s的锁。
这就更神奇了,这条SQL只会更新一行记录,也就是只会锁一行记录,而且并发量并不高,怎么会有锁等待并且等这么久?
正百思不得其解时,定睛一看,怎么监控里还有个执行了25688秒(7个多小时)的大事务?!
查看一下大事务的信息
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX WHERE trx_mysql_thread_id = 10722014\G
*************************** 1. row ***************************
trx_id: 194926675788
trx_state: RUNNING
trx_started: 2024-11-20 23:44:55
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 7353
trx_mysql_thread_id: 10722014
trx_query: NULL
trx_operation_state: NULL
trx_tables_in_use: 0
trx_tables_locked: 0
trx_lock_structs: 4190
trx_lock_memory_bytes: 587304
trx_rows_locked: 4142
trx_rows_modified: 3163
trx_concurrency_tickets: 0
trx_isolation_level: READ COMMITTED
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 10000
trx_is_read_only: 0
trx_autocommit_non_locking: 0
好家伙,锁了4142行记录,修改了3163行记录,作为一个toC的服务,这实在是有点匪夷所思。
但trx_query为null,不清楚执行了哪些SQL,很难定位是哪个业务/代码导致的大事务。
只能再看看这个事务持有哪些锁
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS WHERE LOCK_TRX_ID = 22993881
| lock_id | lock_trx_id | lock_mode | lock_type | lock_table | lock_index | lock_space | lock_page | lock_rec | lock_data |
|---|---|---|---|---|---|---|---|---|---|
| 194926675788:7177:1318939:353 | 194926675788 | X | RECORD | database.tableXXX |
uid_bid_tid | 7177 | 1318939 | 353 | 81681092, 575, 4120 |
| 194926675788:7184:1364347:313 | 194926675788 | X | RECORD | database.tableXXX |
uid_bid_tid | 7184 | 1364347 | 313 | 161498379, 575, 6501 |
| … | 194926675788 | X | RECORD | database.tableXXX |
uid_bid_tid | … | … | … | … |
| 194926675788:566:20738:503 | 194926675788 | X | RECORD | database.tableYYY |
uid_wid | … | … | … | 191628667, 667 |
看到这个锁记录,基本就破案了,这个大事务持有了tableXXX的大量行记录的锁,并且一直没提交,导致了其他事务的update锁等待。
哪来的大事务
虽然锁等待破案了,但是更严峻的问题来了。
锁记录里可以看到,这个大事务不仅持有tableXXX的行锁,也持有了tableYYY的行锁。而tableXXX和tableYYY是风牛马不相及的两个独立业务,怎么会出现在同一个事务里?
并且,4000+的行锁,我们根本没有这样的业务场景,反复排查代码,也根本没有同一个事务操作这两个表的逻辑。
究竟是哪来的大事务💔💔💔
思索再三之后,大胆推测,是不是发生了类似于内存泄漏之类的【事务泄漏】问题,即:
- 某一次请求开启事务之后,没有进行commit或rollback
- 之后的其他请求又复用了这个数据库链接,处在了同一事务里,且也没有进行commit
- 长时间累积导致了大事务
tableXXX和tableYYY的读写操作代码,均没有添加@Transactional注解,与第二点相符。
我们的项目里使用hikari连接池,合理怀疑是不是某些情况下,hikari有什么bug导致了事务既不commit也不rollback。
但道路是曲折的,反复尝试不同的关键词搜索google之后,发现并没有相关的内容。
秉持着“我肯定不是第一个遇到这个问题的人”原则,暂时排除hikari的嫌疑。
经过努力回想和再次排查之后,发现项目里事务并不是全由@Transactional交给框架管理的,某同事在若干年前写了一段手动事务管理的代码
public <T> T manualTransaction(List<String> txManagerNames, Supplier<T> supplier) {
List<TransactionStatus> statues = new ArrayList<>();
List<PlatformTransactionManager> managers = new ArrayList<>();
for (String name : txManagerNames) {
DataSourceTransactionManager manager = (DataSourceTransactionManager) applicationContext.getBean(name);
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
TransactionStatus status = manager.getTransaction(def);
managers.add(manager);
statues.add(status);
}
boolean flag = false;
try {
T t = supplier.get();
flag = true;
return t;
} finally {
for (int i = managers.size() - 1; i >= 0; i--) {
PlatformTransactionManager manager = managers.get(i);
TransactionStatus status = statues.get(i);
if (flag) {
try {
manager.commit(status);
} catch (Exception e1) {
flag = false;
//... 记录日志
}
} else {
try {
manager.rollback(status);
} catch (Exception e2) {
//... 记录日志
}
}
}
}
}
这段代码乍一看没什么问题,commit和rollback都在finally里,怎么都不会执行不到。但再仔细一些,for循环里其实也会抛异常,如果此时manager.getTransaction(def)已经执行成功,开启了事务,那么就会导致这个事务开启之后一直不commit。
至此,终于水落石出。
延伸问题
Q: 如果我tableXXX的update SQL开启了事务,加了@Transactional,能避免这个问题吗?
不能。外部大事务还是需要手动管理,手动commit或者rollback,即tableXXX的update commit也没法让外层的大事务提交。